Introduction
Message queuing services do play an increasingly important role allowing companies to create elastic, cross platform/cross application, asynchronous processing architectures. One of the popular choices for message queuing is RabbitMQ, it is an Advanced Message Queuing Protocol (AMPQ) compliant, well documented, with a broad user base.
The steps below are describing how to build operational highly available redundant RabbitMQ cluster, which will be composed from three servers. The assumption is that clustered servers are residing within a same Data Center. RabbitMQ replication across WAN will function, however will conflict with the principles of the CAP Theorem.
Upon RabbitMQ cluster installation a testing method will be presented as well.
Steps to Configure RabbitMQ Cluster on Lumen Cloud
- Create Server.
We will use the Ubuntu 14 64-bit template for this example, however with a few changes, these steps can be performed on other OS flavours as well.
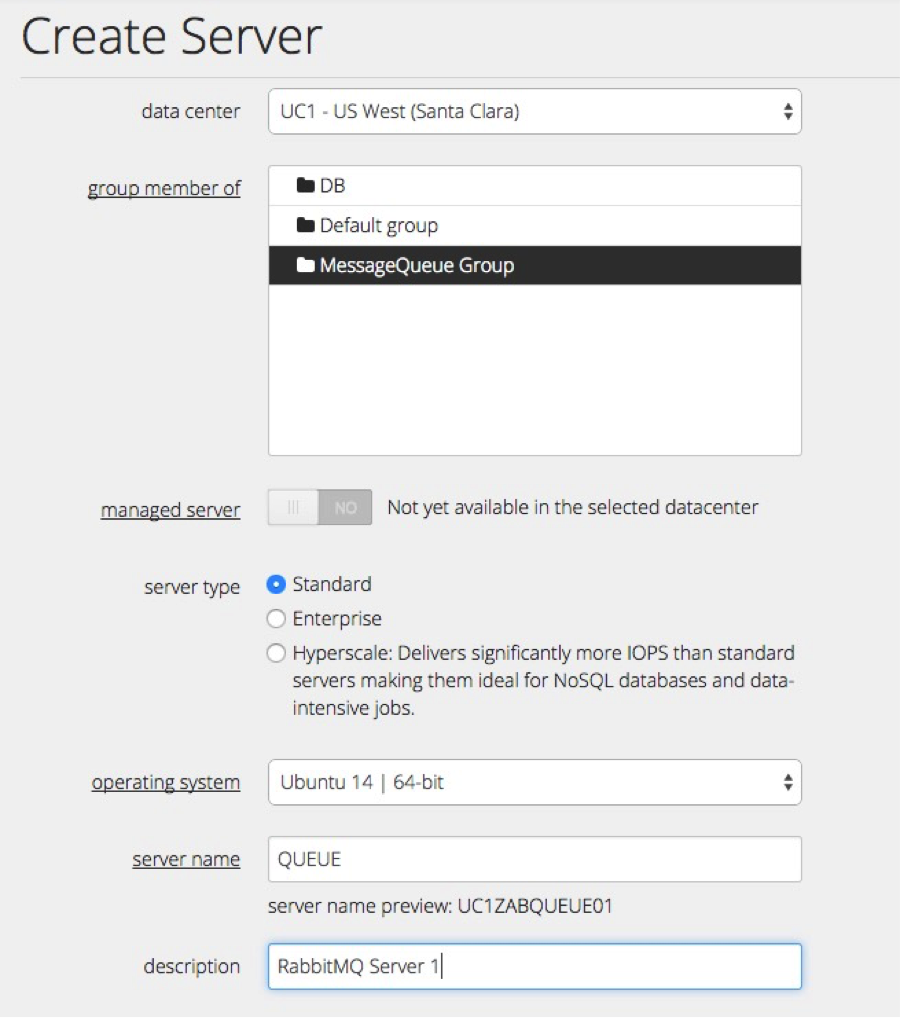
- Install RabbitMQ.
This will become a main queue server. We will use the following script to install the MySQL package using Ubuntu's package manager. You could also create a [blueprint script](https://t3n.zendesk.com/entries/20348448-Blueprints-Script-and-Software-Package-Management) to do this, but since we are only installing on one server for now, we will logon to the server and run the commands manually.
apt-get update apt-get -y install rabbitmq-server
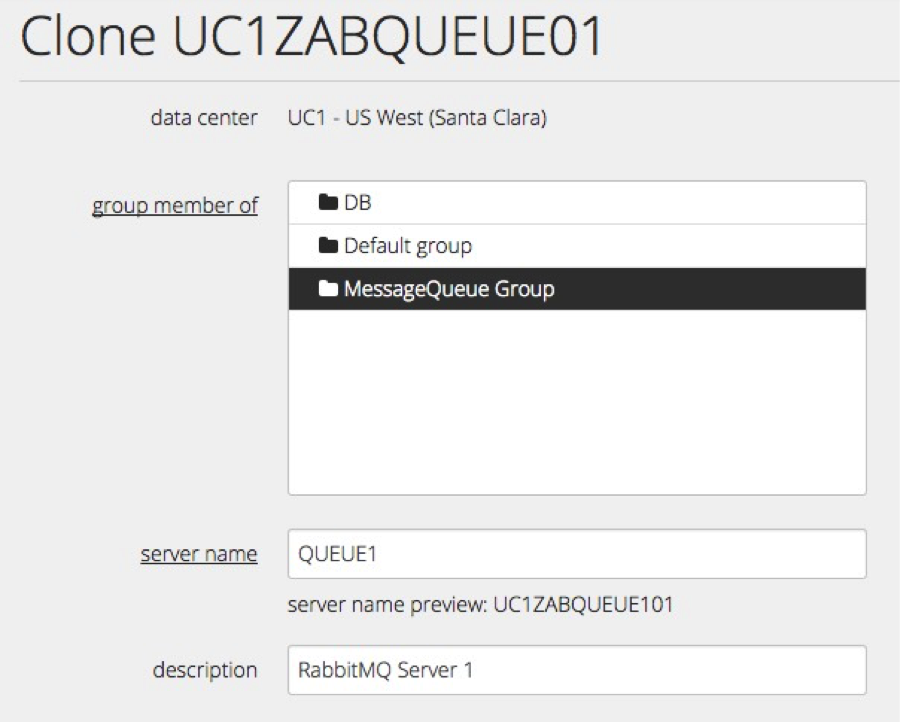
- Clone server.
Now we will use clone method to create second and third messaging queue servers.
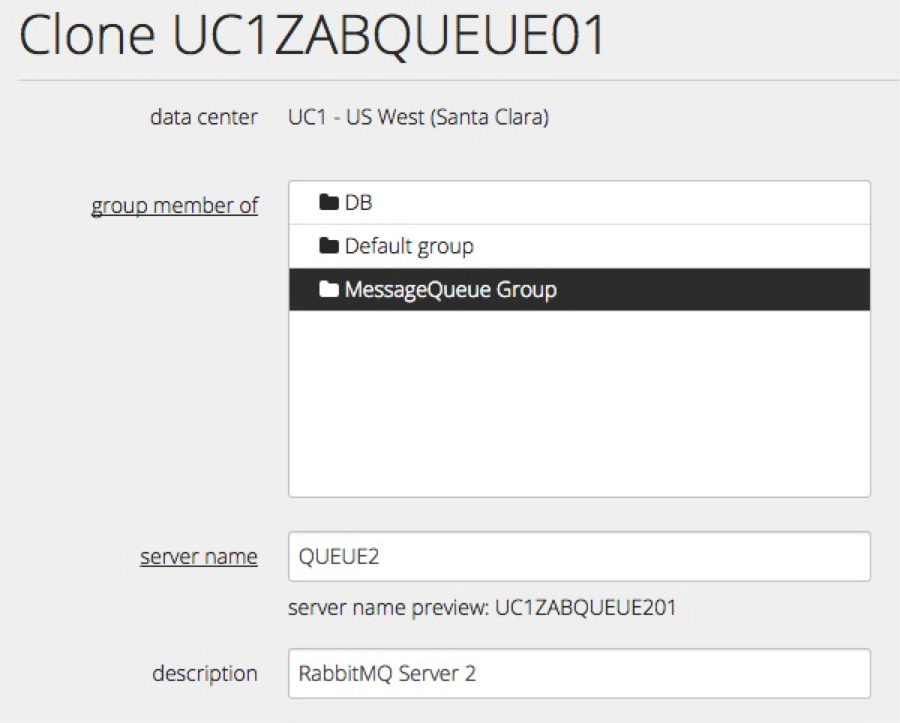
- Configuring RabbitMQ cluster.
To simplify instructions, we will rename hostnames to something less cryptic, and call servers: queue1, queue2 and queue3, by executing following command on respective host.
FIRST_SERVER$ hostname queue1 SECOND_SERVER$ hostname queue2 THIRD_SERVER$ hostname queue3
We'll need to change /etc/hosts file as well to reflect the change across all nodes:10.XX.XX.1 queue1 # master 10.XX.XX.2 queue2 # First slave 10.XX.XX.3 queue3 # Second slave
To begin cluster configuration we will stop RabbitMQ on all three servers with:/etc/init.d/rabbitmq-server stop
Ensure service is stopped properly by examining output from the command - no services should be listed:ps aux | grep '[r]abbitmq-server'
Since we need the same cookie file to be present across all nodes, next we need to copy the cookie from the master to slaves. Running from the master:scp /var/lib/rabbitmq/.erlang.cookie queue1:/var/lib/rabbitmq/ scp /var/lib/rabbitmq/.erlang.cookie queue2:/var/lib/rabbitmq/
Make sure you start nodes after copying the cookie from the master./etc/init.d/rabbitmq-server start
The following commands have to be run on all nodes, except the master (queue1).rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@queue1 rabbitmqctl start_app
To confirm the change took place, we check cluster's status from any connected node:rabbitmqctl cluster_status Cluster status of node rabbit@queue3 ... [{nodes,[{disc,[rabbit@queue1,rabbit@queue2,rabbit@queue3]}]}, {running_nodes,[rabbit@queue1,rabbit@queue2,rabbit@queue3]}, {partitions,[]}] ...done. - HA policy
Finaly, to synck all the queues accross all the nodes we need to run:
rabbitmqctl set_policy ha-all "" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
Testing RabbitMQ cluster
The cluster is ready to be tested. We will create a simple testing scenario to make sure our cluster works as is expected. Using first Python script we are going to submit a message to the messaging queue and using second script we will collect that message. To prepare for testing, we will install Python module to work with RabbitMQ:apt-get install python-pikaNow let's copy and paste the following script in your home directory, and call it "test_send.py"
import pika queue_server='queue1' queue_name="My_First_Queue" message="Hello CLC!" connection = pika.BlockingConnection(pika.ConnectionParameters(host=queue_server)) channel = connection.channel() channel.queue_declare(queue='%s' % queue_name) channel.basic_publish(exchange='', routing_key='%s' % queue_name, body='%s' % message) print " [---->] Sent a message : '%s'" % message connection.close()The script connects to the "queue1" servers and sends a message, which consecutively replicates into the rest of the servers of our new queue cluster:
python test_send.pyTo make sure message has been successfully received, we run:
rabbitmqclt list_queuesWhen we run this command on each of the three clustered servers, you should see:
queue1:/home/rabbit/py$ rabbitmqctl list_queues Listing queues ... My_First_Queue 1 ...done. queue2:/home/rabbit/py$ rabbitmqctl list_queues Listing queues ... My_First_Queue 1 ...done. queue3:/home/rabbit/py$ rabbitmqctl list_queues Listing queues ... My_First_Queue 1 ...done.Output from the command implies that message is waiting in a queue to be used. To test message retrieval, we'll use the following script test_receive.py
import pika queue_name="My_First_Queue" queue_server="queue2" connection = pika.BlockingConnection(pika.ConnectionParameters(queue_server)) channel = connection.channel() channel.queue_declare(queue='%s' % queue_name) def callback(ch, method, properties, body): print " [---->] Received %r" % (body,) channel.basic_consume(callback, queue='%s' % queue_name, no_ack=True) print ' [---->] Waiting for the next messages. To exit press CTRL+C' channel.start_consuming()The script connects to one of the cluster nodes and retrieves the message stored there.
queue3:/home/rabbit/py$ python test_receive.py [---->] Received 'Hello CLC!' [---->] Waiting for the next messages. To exit press CTRL+CWe received our message and can confirm that messaging queue becomes empty:
queue1:/home/rabbit/py$ rabbitmqctl list_queues Listing queues ... My_First_Queue 0 ...done.To learn more about configuration options and features you can consult RabbitMQ manual.